

SQR-097
TAP over QServ using an event-based architecture#
Abstract
The existing CADC-based TAP services that the RSP deploys use JDBC connections to run queries on the QServ catalog data. The current setup lacks crucial query control capabilities - specifically, the ability to stop or monitor long-running queries over large datasets. We propose a new event-based architecture that decouples the TAP service from QServ. This architecture utilizes Kafka queues as the means for messaging between TAP and QServ, with a plan to take advantage of existing systems and knowledge, in particular, Apache Kafka managed by Sasquatch to enable asynchronous query execution with capabilities for query cancellation and monitoring.
1. Introduction#
1.1 Current architecture#
The current implementation connects the CADC TAP service to QServ through a JDBC interface. The service is built using the CADC TAP library and implements the TAP 1.1 protocol. Database connectivity is configured via a JNDI DataSource (jdbc/qservuser), utilizing Apache Tomcat’s connection pooling for persistent JDBC connections to QServ, with the parameters set in the server configuration.
The query execution flow starts when a query is received through the TAP interface, which is then processed by the QServQueryRunner class and executed via the JDBC connection.
Upon completion, results are written to GCS storage and made accessible to users through the UWS result interface, which provides a redirect to the storage location through a Redirect Servlet that is a Rubin specific implementation rather than part of the CADC TAP library.
1.2 Motivation for change#
While this architecture is functional and serves most use cases effectively, it has some limitations in our specific context. QServ operates as a distributed database system handling large datasets, where queries can potentially run for extended periods. In this environment, it is very likely that users might submit inefficient queries that consume substantial resources over long periods.
These types of queries have the potential to overwhelm the system at high concurrency and the current JDBC-based implementation lacks core operational capabilities that would help alleviate this, specifically a mechanism to stop executing queries once started and monitoring capabilities for users for these long-running queries.
The use-case scenario we would like to support that is not currently possible is allowing users to identify that a query has been running longer than they expected, to stop this potentially inefficient query, modify its parameters and restart it.
1.3 Goals and Requirements#
Goals#
The primary goals for this transition are:
Enhance control over query execution
Decouple TAP service from underlying data store to allow for more flexibility in the future
Enable a core feature of allowing cancellation of running queries
Get detailed information about query execution such as progress metrics & status updates.
Backward Compatibility. Also, any changes should be transparent to the user and not change any of the observed behaviour of the TAP service
Requirements#
Integration with the existing UWS job management system & support for both synchronous and asynchronous query execution
Efficient handling of large result sets
Proper error handling and status reporting
Ability to scale to a large number of concurrent users (1-10k initially)
2. System Architecture#
2.1 System Architecture Diagram#
The figure below illustrates the system architecture demonstrating the interactions between TAP and QServ during query execution.
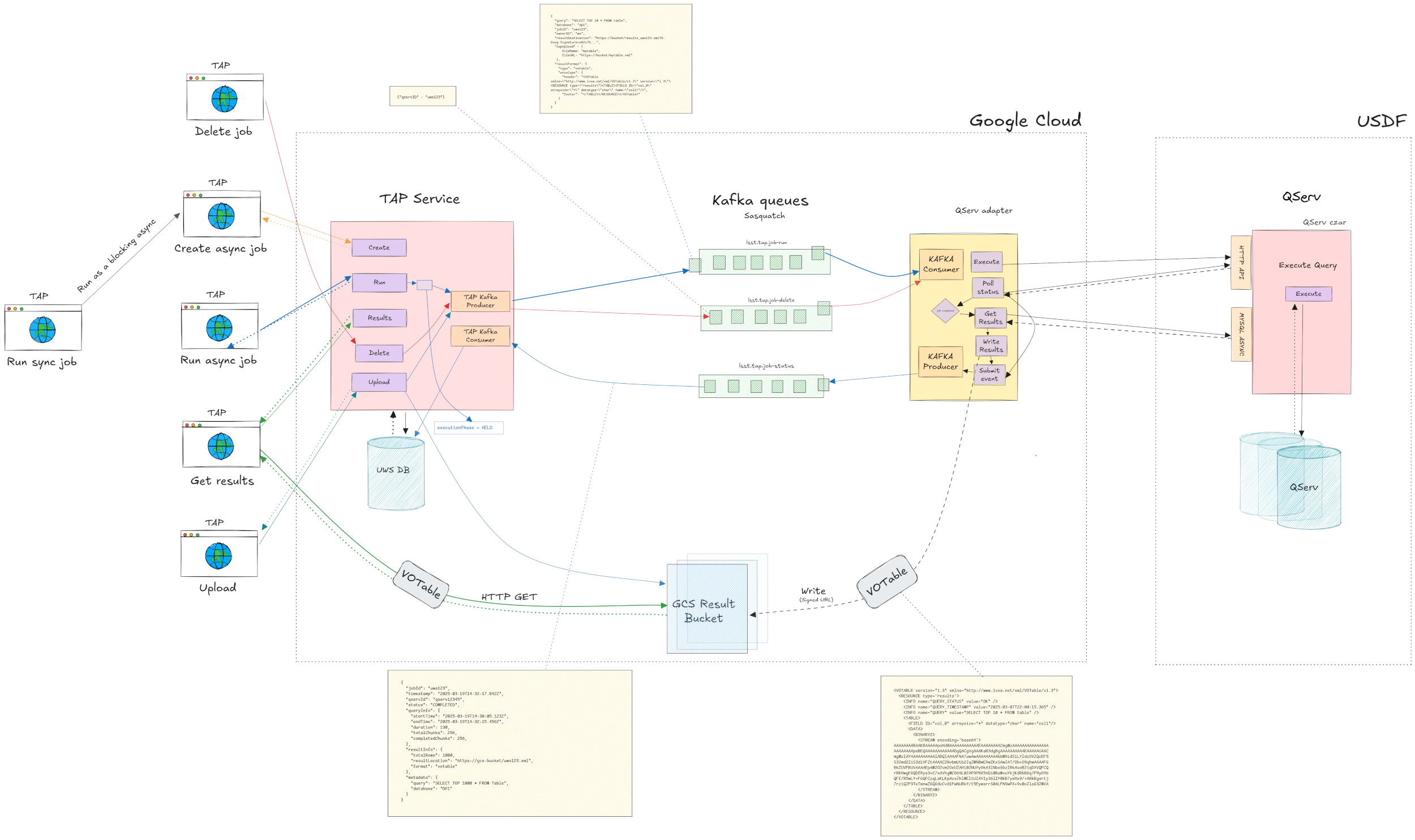
Fig. 1 System Architecture#
Core Components#
TAP Service: CADC TAP service
UWS Database: Stores job information and status
QServ: Distributed database with HTTP REST API for query execution
Kafka (Sasquatch): Event streaming platform
QServ adapter: Will read from Kafka and interact with QServ via existing async and HTTP APIs
Google Cloud Storage (GCS): Store Query VOTable results
Key Technical Elements#
Job ID Correlation: We’ll maintain a mapping between uws jobID and qservID This may be done as an additional field in the UWS table (qservID)
Signed URLs: We may be able to use signed URLs as a means for QServ to write to GCS without credential management
VOTable Envelope: TAP service will provide the metadata structure which QServ is unaware of, so that it can then simply insert the data
Event-Driven Processing: Decouples components for better scalability and allows us to later use alternative Query back-end mechanisms
2.2 Proposed TAP query execution flow (asynchronous queries):#
Job Create Flow#
User submits a create job request.
TAP service creates a record in the UWS database and sets the status to HELD
Job Run Flow#
TAP Service:#
User submits a request to execute a UWS job
TAP service performs query validation, transformation to QServ SQL, and extracts select list with metadata and generates the VOTable envelope
(Optional) TAP service updates the status of the job to QUEUED
TAP service publishes a message to the lsst.tap.job-run Kafka topic
Nothing else required at this point from the TAP Service.
QServ (Adapter & Czar):#
QServ adapter pulls an event from lsst.tap.job-run Kafka queue
QServ adapter sends out a lsst.tap.job-status update event with status = EXECUTING and sends it to the QServ Czar, it then stores the qservID.
Qserv Czar begins the query execution
While executing the query, QServ adapter sends out lsst.tap.job-status events with progress information, such as the number of chunks processed, estimated time remaining, etc. The interval of these updates is TBD, but perhaps every 20% of the total chunks processed would be a good starting point. To get this information it can use either the SQL async interface or the HTTP API.
Qserv Adapter polls Qserv for status checks for job.
Upon completion, Qserv Adapter uses the SQL interface to fetch results and stream them into GCS, using the VOTable envelope provided, ideally using BINARY2 serialization.
QServ adapter writes the results to the GCS bucket, using the signed URL provided
Upon successful writing, it sends out an event to the lsst.tap.job-status with the status of the job (COMPLETED / FAILED / ABORTED).
TAP Service:#
TAP Service pulls events from lsst.tap.job-status.
It then updates the UWS database with the metadata provided in that event.
Events in this case may indicate a Completed job, a job that failed along with metadata on reasons for the failure, or a status of RUNNING to indicate that the job is now executing.
One of the benefits of the new architectue is that it allows us to provide progress information to the user. The initial proposal here is to store this information in the jobdetail UWS table, with each update event appending a new row to that table.
If we find that this is producing too much data, we may also consider introducing a new field in the UWS job table to store the progress information, though this would probably be an implementation-specific defail which would not end up as part of the upstream CADC codebase.
Result Retrieval Flow#
User requests results from the TAP service
TAP service redirects the user to the GCS URL with the results file
User (client) downloads the result file
2.3 Proposed TAP query execution flow (synchronous queries):#
The initial consideration here is to use a sync-over-async mechanism.
In practice, this would mean that as a user makes a sync request, we open a blocking thread which runs the UWS async process until the job is completed.
There are a few possible approaches to how the completion notification will occur:
Option #1: The thread polls the UWS table for updates to the job, perhaps with some sort of exponential back-off to ensure we are not overloading the database with traffic.
This is the simplest approach, though it does come with the downside of introducing additional traffic to the UWS database. We’ll need to run some scalability tests to see how this would affect the system and decide whether this is a viable approach.
Option #2: We maintain a Semaphore in the TAP Service through the use of a REDIS instance. The thread that is waiting for the job to complete will wait on this semaphore, and the UWS job update process will release the semaphore when the job is completed. This would be a more efficient approach, but it does introduce some complexity in the system.
Another consideration would be to actually make the UWS dabatase a REDIS instance. This would allow us to get around the scalability issues of having to poll the database and would allow us to use the semaphore approach without having to introduce another service. However, we would lose the persistence of the UWS database, which in our current plans serves as the Query History source. There are ways to workaround this, perhaps by syncing the job status to a single Wobbly UWS database which Firefly and Nublado could use as the source of query history.
In any case this is probably quite a complex change, so the initial approach is probably to stick with Option #1 and see how it performs, before deciding if we need to move to a more complex solution.
Job Delete Data Flow#
TAP Service:#
Upon receiving a request to delete a job send an event to the lsst.tap.job-delete topic
Update the status of the UWS job to set it to DELETED
QServ adapter:#
Qserv pulls event form job-delete queue.
Upon receiving a request to delete a job, sends a request to either API of QServ to stop and delete query.
Our approach here would be to set the job to DELETED in UWS before sending off the event in Kafka. This ensures that the job is marked as deleted, in case the user checks the status before the event is processed by QServ.
Temporary Upload Data Flow#
The temporary TAP Upload process will look something like this:
TAP Service:#
Upon receiving a request to do a TAP_UPLOAD query, we take the uploaded file and push it to GCS.
Send the GCS URL along with a name for the file as additional metadata in the lsst.tap.job-run event.
QServ adapter:#
Upon receiving a job-run request which includes a temporary table upload upload, se the GCS URL to upload the file into QServ via the HTTP API.
Once table has been uploaded, initialize the query via either QServ API and send an event to job_status that the job is EXECUTING.
Upon completion, send an event to the lsst.tap.job-status topic with the status of the job (COMPLETED / FAILED / ABORTED).
Delete table from QServ via the HTTP API of QServ
This is a preliminary design for the temporary TAP upload which requires some more considerations and may be changed in the future as we get further into the implementation.
3. Event Schemas#
3.1 Job run#
Job run Topic Schema#
{
"type": "object",
"required": ["query", "jobID", "ownerID", "resultDestination", "resultFormat"],
"properties": {
"query": {
"type": "string",
"description": "The SQL query to be executed by QServ"
},
"maxrec": {
"type": "integer",
"description": "The TAP MAXREC parameter indicating maximum row limit"
},
"database": {
"type": "string",
"description": "The database to query, e.g., 'dp1'"
},
"jobID": {
"type": "string",
"description": "UWS job identifier for correlation"
},
"ownerID": {
"type": "string",
"description": "User identifier who submitted the query"
},
"resultDestination": {
"type": "string",
"description": "Signed GCS URL where QServ should write the results"
},
"resultLocation": {
"type": "string",
"description": "Optional result location for tracking purposes",
},
"resultFormat": {
"type": "object",
"required": ["format", "envelope", "columnTypes"],
"properties": {
"format": {
"type": "object",
"required": ["type", "serialization"],
"properties": {
"type": {
"type": "string",
"enum": ["VOTable"],
"description": "Base format type of the result file"
},
"serialization": {
"type": "string",
"enum": ["TABLEDATA", "BINARY2"],
"description": "Serialization method used for the format"
}
}
},
"envelope": {
"type": "object",
"required": ["header", "footer", "footerOverflow"],
"properties": {
"header": {
"type": "string",
"description": "VOTable header with metadata structure"
},
"footer": {
"type": "string",
"description": "VOTable footer to close the XML structure"
},
"footerOverflow": {
"type": "string",
"description": "VOTable footer to close the XML structure, including an overflow message to indicate data truncation"
}
}
},
"columnTypes": {
"type": "array",
"description": "Array of column type information",
"items": {
"type": "object",
"required": ["name", "datatype"],
"properties": {
"name": {
"type": "string",
"description": "Column name"
},
"datatype": {
"type": "string",
"description": "VOTable datatype"
},
"arraysize": {
"type": "string",
"description": "Optional array size specification for the column"
},
"requiresUrlRewrite": {
"type": "boolean",
"description": "Flag indicating if this column needs URL rewriting",
"default": false
}
}
}
},
"baseUrl": {
"type": "string",
"description": "Base URL to use for access_url fields that require rewriting"
}
}
},
"uploadTables": {
"type": "array",
"description": "Optional information for TAP_UPLOAD queries - can include multiple tables",
"items": {
"type": "object",
"properties": {
"tableName": {
"type": "string",
"description": "Name to give the uploaded table in QServ"
},
"sourceUrl": {
"type": "string",
"description": "GCS URL where the uploaded file was stored by TAP"
},
"schemaUrl": {
"type": "string",
"description": "GCS URL where the schema for the uploaded file was stored by TAP"
}
}
}
},
"timeout": {
"type": "integer",
"description": "Optional timeout in seconds for query execution"
}
}
}
Job run example event#
{
"query": "SELECT TOP 10 * FROM table",
"maxrec": 1000,
"database": "dp1",
"jobID": "uws123",
"ownerID": "me",
"resultDestination": "https://bucket/results_uws123.xml?X-Goog-Signature=a82c76...",
"resultLocation": "https://bucket/results_uws123.xml",
"resultFormat": {
"format": {
"type": "VOTable",
"serialization": "BINARY2"
},
"envelope": {
"header": "<VOTABLE xmlns=\"http://www.ivoa.net/xml/VOTable/v1.3\" version=\"1.3\"><RESOURCE type=\"results\"><TABLE><FIELD ID=\"col_0\" arraysize=\"*\" datatype=\"char\" name=\"col1\"/>",
"footer": "</TABLE></RESOURCE></VOTABLE>",
"footerOverflow": "</TABLE><INFO name=\"QUERY_STATUS\" value=\"OVERFLOW\"/></RESOURCE></VOTABLE>"
},
"columnTypes": [
{
"name": "object_id",
"datatype": "long"
},
{
"name": "ra",
"datatype": "double"
},
{
"name": "dec",
"datatype": "double"
},
{
"name": "access_url",
"datatype": "char",
"arraysize": "*",
"requiresUrlRewrite": true
}
],
"baseUrl": "https://data-dev.lsst.cloud/"
}
}
3.2 Job deletion#
Job delete Topic Schema#
{
"type": "object",
"required": ["executionID", "jobID"],
"properties": {
"executionID": {
"type": "string",
"description": "Internal ID of the job being executed (qservID)"
},
"jobID": {
"type": "string",
"description": "The UWS jobID"
},
"ownerID": {
"type": "string",
"description": "ID of user who submitted the delete request"
},
}
}
Example job delete event#
{
"executionID": "qserv-123",
"jobID" : "uws123",
"ownerID": "me"
}
3.3 Job status#
Job status Topic Schema#
{
"type": "object",
"required": ["jobID", "timestamp", "status"],
"properties": {
"jobID": {
"type": "string",
"description": "UWS job ID"
},
"executionID": {
"type": "string",
"description": "Internal ID of the job being executed (qservID)"
},
"timestamp": {
"type": "string",
"format": "date-time-millis",
"description": "Time of this status update in millisecond precision"
},
"status": {
"type": "string",
"enum": ["QUEUED", "EXECUTING", "COMPLETED", "ERROR", "ABORTED", "DELETED"],
"description": "Current status of the job"
},
"queryInfo": {
"type": "object",
"description": "Info about query execution",
"properties": {
"startTime": {
"type": "string",
"format": "date-time-millis",
"description": "Time when query execution started"
},
"endTime": {
"type": "string",
"format": "date-time-millis",
"description": "Time when query execution completed"
},
"duration": {
"type": "integer",
"description": "Duration of execution in seconds"
},
"totalChunks": {
"type": "integer",
"description": "Total number of QServ chunks to process"
},
"completedChunks": {
"type": "integer",
"description": "Number of chunks processed so far"
},
"estimatedTimeRemaining": {
"type": "integer",
"description": "Estimated seconds remaining to completion"
}
}
},
"resultInfo": {
"type": "object",
"description": "Information about query results",
"properties": {
"totalRows": {
"type": "integer",
"description": "Total number of rows in the result"
},
"resultLocation": {
"type": "string",
"description": "GCS URL where results were written"
},
"format": {
"type": "object",
"properties": {
"type": {
"type": "string",
"enum": ["VOTable"],
"description": "Base format type of the result file"
},
"serialization": {
"type": "string",
"enum": ["TABLEDATA", "BINARY2"],
"description": "Serialization method used for the format"
}
}
}
}
}
"errorInfo": {
"type": "object",
"description": "Information about any errors that occurred",
"properties": {
"errorCode": {
"type": "string",
"description": "Error code, if applicable"
},
"errorMessage": {
"type": "string",
"description": "Human-readable error message"
},
"stackTrace": {
"type": "string",
"description": "Optional stack trace for debugging"
}
}
},
"metadata": {
"type": "object",
"description": "Additional metadata about the query",
"properties": {
"query": {
"type": "string",
"description": "The original query"
},
"database": {
"type": "string",
"description": "Database that was queried"
},
"userTables": {
"type": "array",
"description": "List of any user tables created for TAP_UPLOAD",
"items": {
"type": "string"
}
}
}
}
}
}
Job status for completed query example#
{
"jobID": "uws-123",
"executionID": "qserv-123",
"timestamp": "1711638729477",
"status": "COMPLETED",
"queryInfo": {
"startTime": "1711638729457",
"endTime": "1711638729477",
"duration": 214,
"totalChunks": 167,
"completedChunks": 167
},
"resultInfo": {
"format": {
"type": "VOTable",
"serialization": "BINARY2"
},
"totalRows": 1000,
"resultLocation": "https://bucket/results_uws123.xml",
},
"metadata": {
"query": "SELECT TOP 10 * FROM table",
"database": "dp1"
}
}
Job status with error#
{
"jobID": "uws-123",
"executionID": "qserv-123",
"timestamp": "1711638729477",
"status": "ERROR",
"queryInfo": {
"startTime": "1711638729477",
"endTime": "1711638729477",
"duration": 3,
"totalChunks": 3,
"completedChunks": 1
},
"errorInfo": {
"errorCode": "QSERR-1",
"errorMessage": "Syntax Error at line 1",
"stackTrace": "at QservQueryExecutor.executeQuery..."
},
"metadata": {
"query": "SELECT TOP 10 * FROM dp1.Table",
"database": "dp1",
"userTables": ["my_objects"]
}
}
Result Format & Serialization#
There are three possible formats that we are considering for the results:
VOTable with TABLEDATA serialization
VOTable with BINARY2 serialization (https://www.ivoa.net/documents/VOTable/20241125/PR-VOTable-1.5-20241125.html#tth_sEc5.4)
VOTable-in-parquet https://wiki.ivoa.net/twiki/bin/viewfile/IVOA/InterOpNov2024Apps?filename=votparquet.pdf;rev=1)
The selection is primarily driven by compatibility with the main data consumers, pyvo and Firefly, along with performance optimization considerations.
TABLEDATA serialization will be the simplest to implement, but it is also the least efficient in terms of data transfer. BINARY2 serialization is more efficient, but it is also more complex to implement. VOTable-in-parquet is the most efficient, but it is work in progress and may not be ready for DP1.
The proposal for this technote is to aim to implement BINARY2 serialization for the initial implementation, with a backup plan to use TABLEDATA if BINARY2 is not feasible, and a longer-term goal of moving to VOTable-in-parquet once it is ready.
Datatypes#
We need to ensure that we maintain the data type integrity throughout the data flow. In terms of the VOTable field metadata,0 the source of truth will be the TAP service which will provide the VOTable wrapper that includes the fields to the qserv adapter. The qserv adapter service will then inject the data stream, leaving the field metadata as-is which will ensure consistency of the field metadata.
In terms of the conversion of row data, the process we use is that we pass in the field metadata as a json object with our request to the adapter, which in turn maintains a simple mapping of IVOA datatype to MySQL (QServ) type, and uses this to collect the results from the sql client into python primitive types, and then serializes them into a BINARY2 stream using those types.
We’ve collected a list of known types that will have to be handled through a combination of parsing the TAP_SCHEMA columns table as well as the sdm_schemas for dp02 and obscore. These types which we ensure will be handled are the following:
The list of available datatypes for DP1 include:
char
long
double
float
boolean
int
From the above, the only datatypes for which we expect to have arraysizes that are not null are those of type char.
Note that more complex types like arrays of numerical types are not on our schedule for the initial release (DP1), but we may decide to extend our capabilities for handling these types if it becomes a requirement for future releases.
5. Kafka Topics Structure#
lsst.tap.job-run - Requests to start a query from TAP service towards QServ
lsst.tap.job-delete - Requests to stop & delete a query from TAP service towards QServ
lsst.tap.job-status - Update to job status from QServ towards TAP service
6. Potential Challenges and Considerations#
How do we handle ObsCore queries that return datalinks?#
Currently for obscore queries that return datalinks, the TAP Service will overwrite the obdscore access_url value with the base URL of the TAP service, available to the TAP Service as an env variable.
However, in the new architecture, QServ will be writing the results to GCS, without the results going through TAP, so we need to figure out a way to provide the base URL to QServ so that it can use this in the access_url field of the VOTable.
In the proposal here, we include the base URL in the metadata provided in the lsst.tap.job-run event, which QServ can then use to construct the access_url field in the VOTable.
Should QServ adapter be aware of the UWS job?#
Should we be passing the uws jobID to it, or is the job identification done purely via the qserv query ID? We will have both a qservID and uws jobID in our table, but in the case we use the qserv query ID for this it needs to be indexed.
How do we handle timeouts?#
What happens if Qserv goes down after having picked an event of the queue, and thus is never able to complete the query, in which case we never get a job status update for that query, leading to the case where the job is stuck as “RUNNING” infinitely. We need an approach to catch these cases, a few options to consider: A batch job which checks if jobs have exceeded a given timeout. If so, update it (Perhaps setting it to FAILED?) Upon a user checking the status of a job, we check the duration and time it out if it has exceeded our timeout.
What happens if QServ is down for a long period?#
The event queue would continue to fill up with query events. Once QServ is back up and running, we need to decide if we start from the last offset, i.e. run all queries that were added to the queue, or if we want to have it auto-reset to the latest event. The potential issue with the first approach, is that if the queue grows quite a bit until QServ recovers, it may take a long time to process all events until it is able to start processing the newest ones. From the user’s point of view newer queries will be stuck as HELD for a while, while on the other hand, in all likelihood users would not be actively polling older jobs if they haven’t returned within a reasonable amount of time.
Update: In the updated design where we use the QServ adapter, we either have to configure the adapter to stop pulling jobs until QServ is back, or we live with the fact that jobs will be lost in the meantime.
Authentication#
Qserv is at USDF so we need to figure out the best authentication story here so that Kafka consumer/producer can interact with the cloud idfs. This includes egress traffic from USDF to the cloud, and also ingress traffic from the cloud to USDF. In the updated design where we are using a QServ adapter in front of QServ to handle the Kafka interactions, the authentication story is different, and we now need to ensure that we can access the HTTP and SQL interfaces from Cloud to USDF>
7. QServ adapter Change Requirements#
Add Kafka consumer and Producer#
Add a Kafka consumer in the QServ adapter app which will read from the lsst.tap.job-run, lsst.tap.job-delete topics and act on the messages received.
Add a Kafka producer in the QServ adapter which will send out events for lsst.tap.job-status updates, including:
Job is running
Job has completed, either successfully or with failure
Result Writing Mechanism#
Implement functionality to: Write query results directly to GCS using the provided signed URL
Result Format#
Generate a VOTable for the results. Ideally use the BINARY2 table serialization The VOTable header/footer will be provided in the initial query request.
Correlate UWS job ID with QServ ID#
Upon TAP sending a job-run event, QServ will need to either:
a) Store the mapping between UWS jobID and QServ queryID b) Take the uws jobID that was provided in the event, and send it as part of the job-status event, so that the TAP service can correlate the two.
Ideally, if it can be passed along with every job status event, the TAP can use that to update the UWS job status. Otherwise, we can also use qservID as the key (assuming we have indexed it as a new field in the UWS job table), however the initial correlation still needs to happen, so the initial job-run event would have to contain the uws jobID.
Authentication and Security#
Writing to GCS:#
Qserv should be able to write results to GCS using signed URLs. Also, we need to ensure that the Kafka producer and consumer can interact with the cloud idfs.
Failed queries#
Failed synchronous queries need to be written out as proper VOTable results with error status and messages contained as per the IVOA spec. In this design, probably the best way to handle this is to have QServ include any error messages in the lsst.tap.job-status event, and then have the TAP service update the UWS job with this error message. In the case of a synchronous query the TAP service will then have to generate the VOTable which will contain this error message it got from the lsst.tap.job-status event.
8. QServ adapter Change Requirements#
Datalink access_urls#
As mentioned above, we need to figure out a way to provide the base URL to QServ so that it can use this in the access_url field of the VOTable. This implies some additional logic in QServ to know when to format the results of a query and overwrite the access_url field with the base URL provided.
A simple approach would be that when QServ receives a lsst.tap.job-run event that contains a base URL, it will use this base URL to overwrite the access_url.
In other words the TAP service already knows that it wants the results formatted to replace the base_url, so QServ does not have to make that decision, instead simply identify the access_url.
A slight alternative could be to be more explicit and add metadata in the event to indicate the field name to format, and how to format the row values.
9. TAP Service Change Requirements#
TAP Kafka Consumer#
A Kafka consumer which listens to lsst.tap.job-status topics and updates the UWS database accordingly.
TAP Kafka Producer#
A Kafka producer which sends events to various topics (run query, delete query).
TAP_SCHEMA vs QServ Queries#
The TAP service will need to diffentiate between TAP_SCHEMA queries and QServ queries, with tap_schema queries being executed via JDBC.
QueryRunner#
The above will probably require generic QueryRunner and JobExecutor interfaces that define the interfaces required for us to submit queries via a Kafka producer.
Synchronous Queries#
Depending on which implementation we choose, we may have to customize the QueryRunner to run sync over async, and then introduce a synchronization mechanism like the Semaphore described. These are probably specific to our use case, but perhaps the interfaces can be such to allow this to be done via custom implementations.
Job Cancellation#
Cancellation of jobs will involve using our Kafka plugin to generate a delete event and send it via the TAP Kafka producer to Qserv, then updating the UWS job to set the appropriate flags/fields in UWS.
TAP Upload#
The TAP_UPLOAD process will require the TAP service to push the file to GCS and then send the GCS URL along with the file name to the QServ Kafka producer.
Storing job results endpoint in UWS#
The TAP Service needs to read the results URL from a completed jobs and store it in UWS. However, we use a redirect servlet to serve the results, so we need to store the redirect URL in UWS, not the GCS URL.
9. Batch maintenance job to clean up old & jobs that have timed out#
We need to have a batch job that runs periodically to clean up old jobs that have been completed, and also jobs that have timed out. This may occur in situations where QServ goes down and is unable to send a job status update, or if the job is stuck in a running state for an extended period.
To address this we could have a batch job that runs periodically to check the status of jobs that have been running for an extended period, and if they have exceeded a certain timeout, mark them as failed. The timeout would be set to a value close and above what the QServ query timeout is set to.
We could also potentially utilize the QServ REST HTTP API which has a status endpoint to check the status of a query. This would allow us to check the actual status of the job before marking it as failed.